The Auditability-Accuracy Tradeoff
by Lukas Galke Poech
Monitoring reasoning traces of large language models is currently one of the most promising methods to detect when language models do not behave as intended1 – for instance, when they suffer from emergent misalignment2.
However, emergent communication research has shown that language models may drift away from human-interpretable communication protocols when trained for task success alone3. This raises the question of how long language model reasoning will be legible to humans, and whether we can incentivize legibility without sacrificing task performance.
In our recent work on training language models to defer their reasoning to a symbolic reasoning engine (Prolog), we have encountered a tradeoff between the auditability of the reasoning traces and the accuracy of the model on the task. See Figure 1 for an overview.
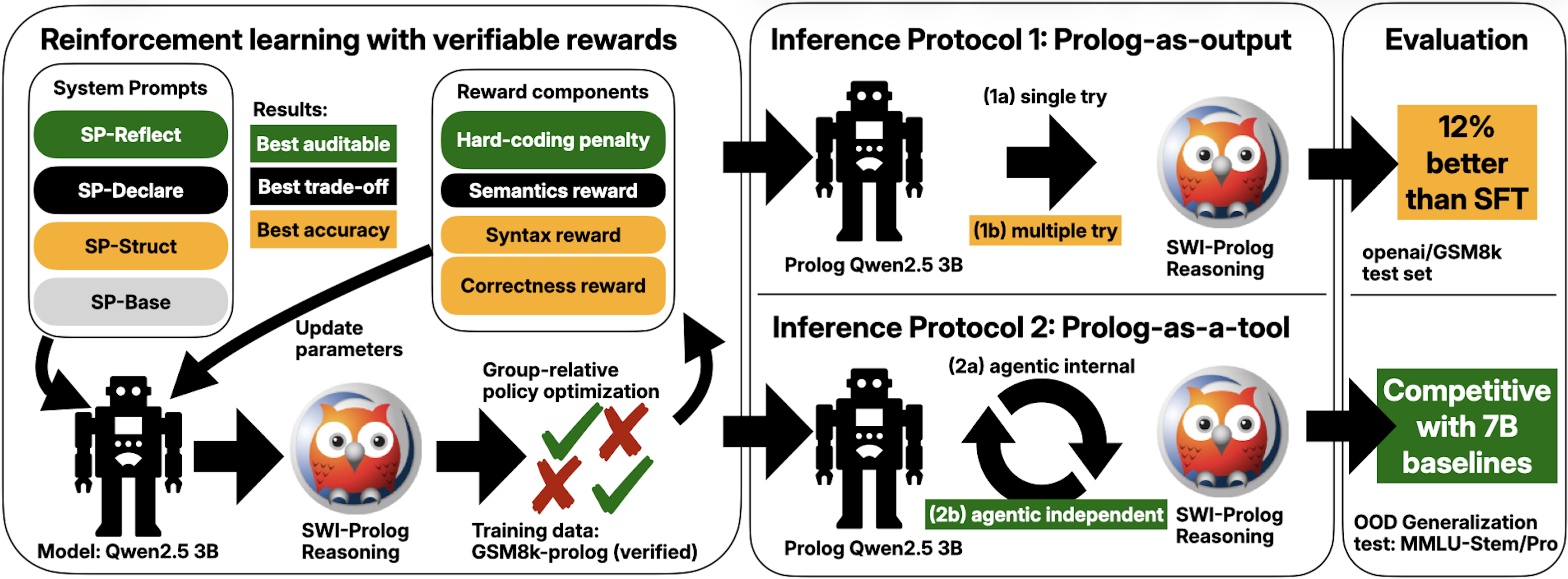
In our experiments, we found that training for task success – with only mild Prolog syntax and format rewards – led to the best task performance. However, the language models then still conducted the majority of their reasoning in natural language and only encoded the final output in Prolog syntax (akin to a print statement in other programming languages). This can be regarded as a form of reward hacking, which is particularly concerning as reward hacking was recently linked to emergent misalignment4.
We then increased the incentives for deferring the reasoning to Prolog through further reward signals. We see that the added incentives successfully combat the reward hacking we observed earlier, but at the same time lead to a noticable decline in task accuracy. A balanced version at least reached 93% structural validty but accuracy drops from 90% to 74%.
Alongside accuracy, the results on GSM8k below show two proxies for auditability: (i) structural validity measuring whether there is more than one Prolog statement, and (ii) semantic similarity, measuring the cosine embedding distance against a ground truth.
| Configuration | Accuracy | Structural Validity | Semantic Similarity |
|---|---|---|---|
| Outcome-optimized (SP-Struct, Rwd1) | 89.87% | 1.60% | 8.27% |
| Structure-optimized (SP-Declare, Rwd3) | 62.40% | 90.40% | 62.67% |
| Balanced (SP-Declare, Rwd2) | 73.60% | 92.53% | 62.13% |
Assuming this auditability-accuracy trade-off generalizes beyond our Prolog setting, it will be very difficult to retain chain-of-thought legibility without loss of accuracy. Future work needs to consider alternative ways to monitor reasoning traces that still work when the reasoning diverges from natural language.
In the paper, accepted to ACL 2026 Findings, we explore this trade-off systematically through three different system prompts and three rewards suites in conjunction with GRPO training, and compare with an SFT baseline.
Based on: Niklas Mellgren, Peter Schneider-Kamp, & Lukas Galke Poech (2026 ACL Findings) Training Language Models to Use Prolog as a Tool.
References
-
Korbak, T., Balesni, M., Barnes, E., Bengio, Y., Benton, J., Bloom, J., … & Mikulik, V. (2025). Chain of thought monitorability: A new and fragile opportunity for ai safety. arXiv preprint arXiv:2507.11473. ↩
-
Betley, J., Warncke, N., Sztyber-Betley, A., Tan, D., Bao, X., Soto, M., … & Evans, O. (2026). Training large language models on narrow tasks can lead to broad misalignment. Nature, 649(8097), 584-589. ↩
-
Lazaridou, A., Potapenko, A., & Tieleman, O. (2020, July). Multi-agent communication meets natural language: Synergies between functional and structural language learning. In Proceedings of the 58th annual meeting of the association for computational linguistics (pp. 7663-7674). ↩
-
MacDiarmid, M., Wright, B., Uesato, J., Benton, J., Kutasov, J., Price, S., … & Hubinger, E. (2025). Natural emergent misalignment from reward hacking in production rl. arXiv preprint arXiv:2511.18397. ↩